Source: securityboulevard.com – Author: Dana Epp
What if I told you that many APIs leverage custom HTTP headers to drive business logic and behavior?
Would you know which ones they are?
This isn’t just about API requests but web apps in general. Anything that speaks over HTTP has the ability to drive behavior from the request and response headers. To get a good understanding of what is commonly used, Mozilla has some great documentation you can check out.
In this article, I’ll show you how to leverage Burp Suite’s Bambda filters to parse HTTP headers and detect uncommon ones for you automatically. I’ll even show you a neat way to highlight interesting records right in the Proxy history and document them directly in the Notes field for easy access.
Let’s get right to it…
Determining “common” HTTP headers
No web app or API will follow the same guidelines as expected regarding HTTP headers. So, saying a header is “common” isn’t too realistic.
I mean, if you look at Daniel Miessler’s SecList repo, you could use something like the http-request-headers-fields-large.txt wordlist as a guide, but honestly, that’s overkill.
Many of those headers are rarely used, and it’s at THOSE times you want to have them called out. So building a “common” wordlist should encapsulate what we see in most HTTP requests and responses.
If you comb through Mozilla’s documentation, you can generate a quick wordlist that might look something like this:
accept-patch
accept-ranges
access-control-allow-credentials
access-control-allow-headers
access-control-allow-methods
access-control-allow-origin
access-control-expose-headers
access-control-max-age
age
allow
alt-svc
cache-control
clear-site-data
connection
content-disposition
content-encoding
content-language
content-length
content-location
content-range
content-security-policy
content-transfer-encoding
content-type
cross-origin-embedder-policy
cross-origin-opener-policy
cross-origin-resource-policy
date
delta-base
etag
expect-ct
expires
feature-policy
host
im
keep-alive
last-modified
link
location
pragma
proxy-authenticate
public-key-pins
referrer-policy
retry-after
server
set-cookie
strict-transport-security
tk
trailer
transfer-encoding
upgrade
vary
via
warning
www-authenticate
x-content-type-options
x-frame-options
x-permitted-cross-domain-policies
x-xss-protectionSee anything there that should be there that isn’t? Add it. Don’t like what I added? Remove it. It’s your wordlist. Tailor it to your target.
Using this common HTTP header wordlist as a template, let’s go about building a Burp Bambda filter that can use it.
Building our Bambda Filter
So if you are new to Bambda filters, I recommend you check out my article on Writing Burp Bambda Filters Like a Boss. It details what Bambdas are, why you should care, and how to get started.
For this example, I am going to introduce a couple of new concepts around annotations.
An annotation takes Bambda filtering to a new level because we can now alter Proxy History records in Burp Suite based on filter criteria. This will let us change the highlighted color of interesting records and can even allow us to insert data directly into the Notes field for review later.
Preparing our wordlist
Now what follows is some opinionated Java code. I don’t profess to be a ‘leet Java developer, nor would I say this is the only way to do it. But it works. At least for me. YMMV.
As the wordlist could change based on need, I want to edit it easily. So, putting it as a String[] array makes that nice.
However, I am also lazy and want to leverage the simplicity and powerful search capabilities built into Lists/ArrayLists. So I will convert the array into a Java List object.
String[] standardHeaders = {
"accept-patch",
"accept-ranges",
"access-control-allow-credentials",
"access-control-allow-headers",
"access-control-allow-methods",
"access-control-allow-origin",
"access-control-expose-headers",
"access-control-max-age",
"age",
"allow",
"alt-svc",
"cache-control",
"clear-site-data",
"connection",
"content-disposition",
"content-encoding",
"content-language",
"content-length",
"content-location",
"content-range",
"content-security-policy",
"content-transfer-encoding",
"content-type",
"cross-origin-embedder-policy",
"cross-origin-opener-policy",
"cross-origin-resource-policy",
"date",
"delta-base",
"etag",
"expect-ct",
"expires",
"feature-policy",
"host",
"im",
"keep-alive",
"last-modified",
"link",
"location",
"pragma",
"proxy-authenticate",
"public-key-pins",
"referrer-policy",
"retry-after",
"server",
"set-cookie",
"strict-transport-security",
"tk",
"trailer",
"transfer-encoding",
"upgrade",
"vary",
"via",
"warning",
"www-authenticate",
"x-content-type-options",
"x-frame-options",
"x-permitted-cross-domain-policies",
"x-xss-protection"
};
List headersList = Arrays.asList(standardHeaders);Parsing the HTTP headers
With our wordlist defined and ready to go, we can now iterate over the response headers and look for any header that isn’t in our defined common list. If we find anything, we add it to our list of unexpected headers.
This was why I like to use a List object. The method .contains() makes it braindead easy to find if a header matches any records in our defined wordlist or not.
var headers = requestResponse.response().headers();
List unexpectedHeaders = new ArrayList();
for( var header : headers ) {
var headerName = header.name().toLowerCase();
if( !headersList.contains(headerName) ) {
unexpectedHeaders.add(headerName);
}
} Annotating interesting Proxy History records
Once we have parsed through all headers in an HTTP response, all unexpected headers are recorded, and we can now bubble that up into the UI.
We do this by using the Montoya API that now exposes the .annotations() interface. This didn’t exist when I first wrote about writing Bambda filters like a boss. But it does now. So let’s use it!
if( unexpectedHeaders.size() > 0 ) {
requestResponse.annotations().setHighlightColor( HighlightColor.GRAY );
requestResponse.annotations().setNotes(
"Non-standard Headers: " + String.join( ",", unexpectedHeaders )
);
}
else {
requestResponse.annotations().setHighlightColor( HighlightColor.NONE );
requestResponse.annotations().setNotes("");
} As you can see, it is extremely easy to highlight records and even push data into the Notes field of a record.
TIP: When debugging Bambdas, I have previously said it sucks that you can’t easily get access to watch variables and dump data. With access to annotations now, you COULD use .setNotes() as a last-ditch effort to dump data as you debug a Bambda script.
Just remember to reset it so you don’t leave debug data in the Notes. I do that in the else block specifically for that reason.
A cautionary warning
The above code works. But it does have one potential downside.
If any BApp extensions are already color-coding records or populating the Notes field with data, this Bambda filter may trample over those annotations. You could add some logic to check for that with .hasHighlightColor() and .hasNotes(), but I didn’t feel I needed to for this example.
My thinking is that if you are applying a Bambda filter to look for uncommon headers, you are actively seeking those records out and will be happy to modify the records accordingly.
If not, adjust the code to your needs.
The complete Bambda Filter code
if( !requestResponse.hasResponse() )
{
return false;
}
String[] standardHeaders = {
"accept-patch",
"accept-ranges",
"access-control-allow-credentials",
"access-control-allow-headers",
"access-control-allow-methods",
"access-control-allow-origin",
"access-control-expose-headers",
"access-control-max-age",
"age",
"allow",
"alt-svc",
"cache-control",
"clear-site-data",
"connection",
"content-disposition",
"content-encoding",
"content-language",
"content-length",
"content-location",
"content-range",
"content-security-policy",
"content-transfer-encoding",
"content-type",
"cross-origin-embedder-policy",
"cross-origin-opener-policy",
"cross-origin-resource-policy",
"date",
"delta-base",
"etag",
"expect-ct",
"expires",
"feature-policy",
"host",
"im",
"keep-alive",
"last-modified",
"link",
"location",
"pragma",
"proxy-authenticate",
"public-key-pins",
"referrer-policy",
"retry-after",
"server",
"set-cookie",
"strict-transport-security",
"tk",
"trailer",
"transfer-encoding",
"upgrade",
"vary",
"via",
"warning",
"www-authenticate",
"x-content-type-options",
"x-frame-options",
"x-permitted-cross-domain-policies",
"x-xss-protection"
};
List headersList = Arrays.asList(standardHeaders);
var headers = requestResponse.response().headers();
List unexpectedHeaders = new ArrayList();
for( var header : headers ) {
var headerName = header.name().toLowerCase();
if( !headersList.contains( headerName ) ) {
unexpectedHeaders.add( headerName );
}
}
if( unexpectedHeaders.size() > 0 ) {
requestResponse.annotations().setHighlightColor( HighlightColor.GRAY );
requestResponse.annotations().setNotes(
"Non-standard Headers: " + String.join( ",", unexpectedHeaders )
);
}
else {
// Maybe don't trample on existing Notes in the future??
requestResponse.annotations().setHighlightColor( HighlightColor.NONE );
requestResponse.annotations().setNotes("");
}
return true; Seeing it in action
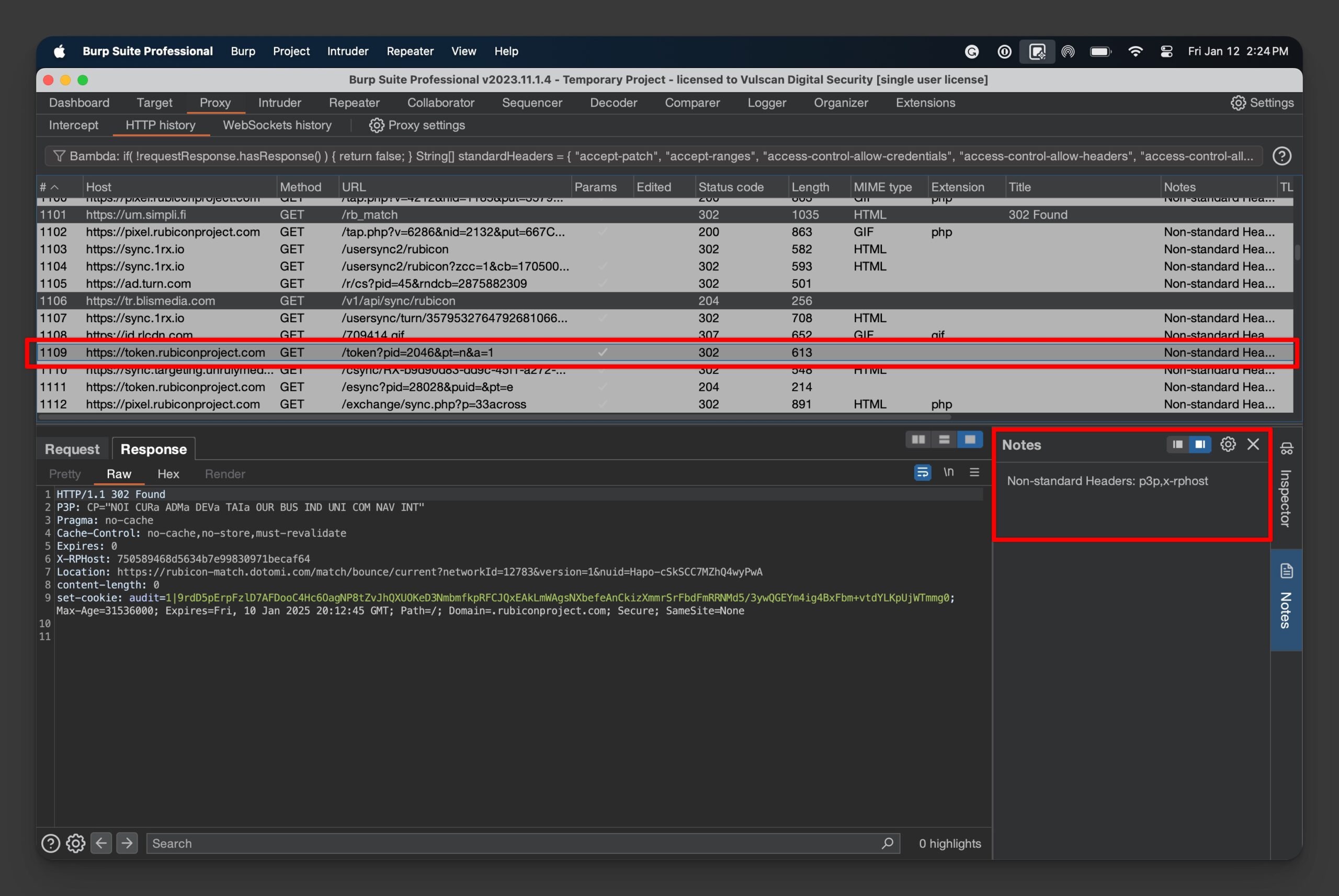
Here is what my Bambda filter looks like in action:

Notice how the Notes field is populated with the uncommon HTTP headers detected. And that records that have such headers are highlighted in gray.
I have saved this filter code as a JSON file called uncommonHeaders.json and load it anytime I want to check for uncommon headers.
When I see an uncommon header for a project that I am not interested in, I add it to the array and apply it against the data, which reapplies the annotations, removing highlighting and notes to show only those records that I am interested in.
I save that new filter out specific to the project (i.e., target-uncommonHeaders.json) so that in the future, I can compare headers as I try to understand how they impact the business logic on the API.
Conclusion
Bambda filter helps in a variety of use cases and provides extreme flexibility. In this article, we saw how we can leverage Bambda filters to highlight records that have uncommon HTTP headers using annotations automatically.
This makes the API security testing process faster and adds extra visibility when managing large amounts of data while making it easy to track manually reviewed issues.
I hope you find the code useful during your next engagement.

One last thing…

Have you joined The API Hacker Inner Circle yet? It’s my FREE weekly newsletter where I share articles like this, along with pro tips, industry insights, and community news that I don’t tend to share publicly. If you haven’t, subscribe at https://apihacker.blog.
The post Detecting Uncommon Headers in an API using Burp Bambda Filters appeared first on Dana Epp’s Blog.
*** This is a Security Bloggers Network syndicated blog from Dana Epp's Blog authored by Dana Epp. Read the original post at: https://danaepp.com/detecting-uncommon-headers
Original Post URL: https://securityboulevard.com/2024/01/detecting-uncommon-headers-in-an-api-using-burp-bambda-filters/
Category & Tags: Security Bloggers Network,API Hacking Techniques,API Hacking Tools – Security Bloggers Network,API Hacking Techniques,API Hacking Tools
Views: 8


















































