

THREATPOST
One easily disproved conspiracy theory linked the ~six-hour outage to a supposed data breach tied to a Sept. 22 hacker forum ad for 1.5B Facebook user records.
As of Monday night, Facebook had crawled back from what may have been its longest blackout ever and apologized for the mass outage that left billions of users locked out of Facebook, Instagram, WhatsApp, Messenger and Oculus VR for about six hours.

In a Monday night blog post, Santosh Janardhan Facebook’s vice president of infrastructure gave some details about how the house of cards came tumbling down, confirming the border gateway protocol (BGP) and DNS problems that experts at Cloudflare had already detected.
Janardhan said that the company’s engineering crew had traced the source of the problem to a configuration change on the backbone routers: a change to routers that coordinate network traffic between data centers that fractured Facebook’s entire internal backbone.
“Our engineering teams have learned that configuration changes on the backbone routers that coordinate network traffic between our data centers caused issues that interrupted this communication,” Janardhan wrote. “This disruption to network traffic had a cascading effect on the way our data centers communicate, bringing our services to a halt.”
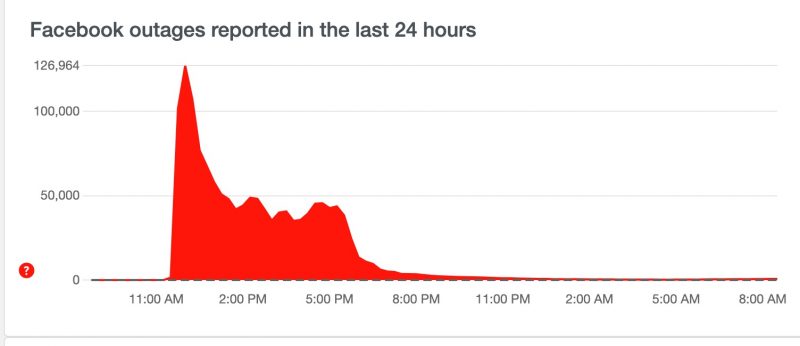
Facebook outage. Source: DownDetector.
That’s it, he said: no cyberattack, no compromised user data, just Facebook shooting itself in the foot by mistake.
Our services are now back online and we’re actively working to fully return them to regular operations. We want to make clear at this time we believe the root cause of this outage was a faulty configuration change. We also have no evidence that user data was compromised as a result of this downtime.
When it comes to gauging Facebook’s worst blackout ever, accounts vary: CNBC reported that Monday’s outage was the longest downtime that Facebook has experienced since 2008, when a bug knocked its site offline for about a day, affecting some 80 million users. (Facebook’s user base has blossomed to 3 billion users since.)
But in 2019, a one-hour blackout was deemed “catastrophic” and called the “worst outage ever.” That 2019 outage was similarly tied to a server configuration change.
In Monday evening’s post, Janardhan apologized to “all the people and businesses around the world who depend on us,” explaining that recovering systems took so long because Facebook’s internal tools were also affected.
“We are sorry for the inconvenience caused by today’s outage across our platforms. We’ve been working as hard as we can to restore access, and our systems are now back up and running. The underlying cause of this outage also impacted many of the internal tools and systems we use in our day-to-day operations, complicating our attempts to quickly diagnose and resolve the problem.” —Santosh Janardhan
How Did Facebook Disappear?
On Monday, Cloudflare engineering director Celso Martinho and edge network technical lead Tom Strickx gave a more detailed explanation of what happened, explaining BGP’s role in keeping Facebook’s content flowing to the masses.
“It’s a mechanism to exchange routing information between autonomous systems (AS) on the Internet,” they wrote. “The big routers that make the Internet work have huge, constantly updated lists of the possible routes that can be used to deliver every network packet to their final destinations. Without BGP, the Internet routers wouldn’t know what to do, and the Internet wouldn’t work.”
They described the Internet as, literally, a network of networks, bound together by BGP. “BGP allows one network (say Facebook) to advertise its presence to other networks that form the Internet,” the Cloudflare experts wrote. During the outage, Facebook wasn’t advertising its presence, meaning that ISPs and other networks couldn’t find Facebook’s network.
During the outage, both Facebook’s BGP records and its domain name system (DNS) records disappeared. DNS is a service that allows the internet to run by translating domains such as Facebook.com into IP addresses and vice versa. On Monday, Facebook’s DNS servers were unavailable, meaning that DNS resolvers couldn’t respond to queries asking for the IP address of facebook.com, Cloudflare said.
John Bambenek, principal threat hunter at IT/security operations firm Netenrich, told Threatpost on Monday that the core protocols that make up the internet are getting a bit creaky at this point. Created in the 70s and 80s, they “were not designed with the scale of the Internet as it exists today,” he commented.
“They also can be very susceptible to human error where small changes can create catastrophic outages, which we see every year or so,” Bambenek continued. “In some ways, this problem will get worse as these protocols are taken for granted, and those who helped develop and implement them are beginning to reach retirement age.”
Data Breach Conspiracy Theories Bubble Up
As Vice reported, conspiracy theories about the outage being related to a data breach managed to spread even without Facebook and all of its hoax-disseminating messaging apps.
One of the most popular theories about the outage concerned a supposed attack that led to 1.5 billion Facebook records being sold on the RaidForums criminal forum. The conspiracy sprang from a Sept. 22 post from a supposed company called X2Emails that advertised “[a] database which hold more than 1.5b Database of Facebook these database scraped this year and 100% emails are included and phone as well.”

RaiderForum screen capture. Source: Motherboard Vice.
The conspiracy theory was easy to dismiss: First, the author said straight up that the data was scraped, meaning that it wasn’t compromised data coming from a threat actor with internal access.
Jake Williams, co-Founder and CTO at incident response firm BreachQuest, told Threatpost on Monday that “This wouldn’t be the first time we’ve seen scammers with scraped data try to capitalize on an outage or related news about an organization to cash in.”
Not to downplay the damage that can be done with scraped data, that is: In July, just days after a data-scraping operation aimed at LinkedIn was discovered, evidence came to light that in a popular hacker forum that the vast amount of lifted data was being collated and refined to identify specific targets.
Source: https://threatpost.com/facebook-blames-outage-on-faulty-router-configuration/175322/

Views: 3


















































