
Source: securityboulevard.com – Author: Dariel Marlow
In today’s data-driven world, organizations are faced with an ever-increasing volume of data from various sources. To extract meaningful insights and drive informed decision-making, it is essential to have a well-structured and scalable data management strategy in place. This is where data lakes, combined with AWS services, come into play.
In this blog post, we will explore how organizations can transform data chaos into data mastery by building and scaling data lakes using AWS services.
Understanding Data Lakes
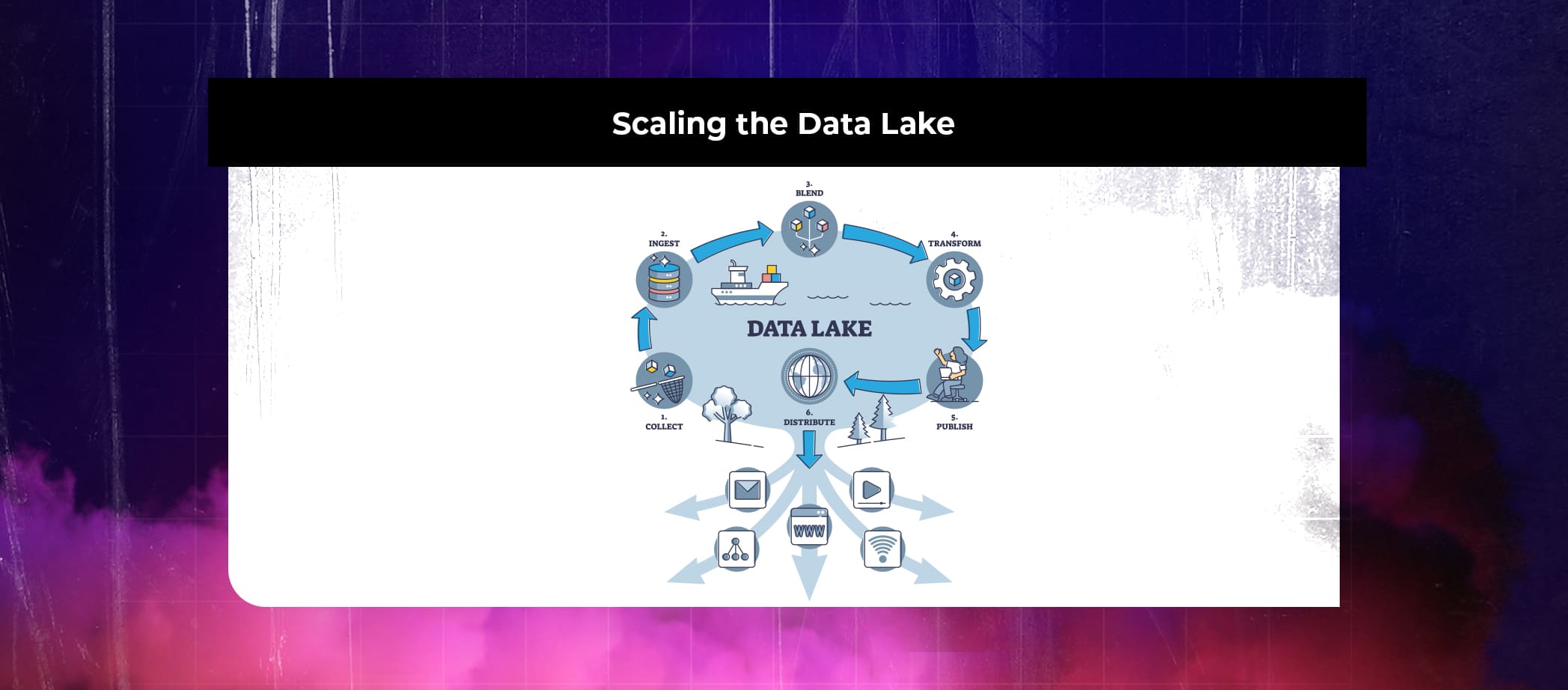
A data lake is a centralized repository that allows organizations to store and analyze vast amounts of structured and unstructured data in its raw form. Unlike traditional data warehouses, data lakes provide flexibility, scalability, and the ability to process data in various formats without the need for predefined schemas. AWS offers a comprehensive set of services to build and scale data lakes efficiently.
Also Read: Unlocking the Four C’s of Cloud-Native Security
Choosing the Right AWS Services
To create and expand data lakes, AWS offers a wide range of services.
Here are some key services to consider:
Amazon S3 (Simple Storage Service)
Amazon S3 is the foundation of a data lake architecture. It provides durable and scalable object storage, enabling organizations to store vast amounts of data reliably. With features like versioning and lifecycle management, S3 allows efficient data management and cost optimization.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that helps prepare and transform data for analysis. It provides capabilities for data cataloguing, data discovery, and automatic schema inference. Glue supports various data sources and can be used to create ETL pipelines to move data from source systems into the data lake.
Amazon Athena
Amazon Athena is an interactive query service that allows organizations to analyze data directly in S3 using standard SQL. It eliminates the need to set up and manage infrastructure, as it works directly on the data stored in S3. Athena provides fast and cost-effective querying capabilities for ad-hoc analysis and exploration.
AWS Glue DataBrew
AWS Glue DataBrew is a visual data preparation tool that makes it easy to clean and normalize data for analysis. It provides a visual interface to explore, transform, and validate data without writing code. DataBrew integrates seamlessly with other AWS services, allowing organizations to streamline the data preparation process.
Amazon Redshift
Amazon Redshift is a fully managed data warehousing service that can be used alongside a data lake to perform complex analytical queries. Redshift provides high-performance and scalable data warehouse capabilities, allowing organizations to store and analyze large datasets efficiently.
Architecting the Ideal Data Lake Framework
To build a scalable and robust data lake architecture with AWS services, follow these steps:
Define your data lake requirements
Identify the data sources, types of data, and analytics use cases. Determine the required data ingestion frequency and define data governance policies.
Configure Amazon S3
Make an S3 bucket to hold unprocessed data. For improved performance and cost-effectiveness, take into account splitting the data.
Use AWS Glue for data cataloguing
Create a data catalogue using AWS Glue to keep track of data assets, schemas, and metadata. This enables easy discovery and exploration of data within the data lake.
Implement data ingestion pipelines
Use AWS Glue or other ETL tools to build data ingestion pipelines. Extract data from various sources, transform it, and load it into the data lake. Schedule the pipelines to ensure regular updates.
Leverage AWS Glue DataBrew for data preparation
To visually clean, manipulate, and evaluate data, use DataBrew. For guaranteeing data consistency and quality, this step is essential.
Enable data querying with Amazon Athena
Create tables and define schemas in Athena to enable SQL-based querying on the data lake. Optimize query performance by partitioning data and using appropriate data formats.
Enhance analytics capabilities with Amazon Redshift
Use Redshift alongside the data lake to perform complex analytical queries and build data models for reporting and visualization.
Scaling the Data Lake
As the volume and variety of data grow, it is important to scale the data lake architecture. AWS provides several options for scaling data lakes:
Partitioning and compression
Implement partitioning strategies to optimize query performance and reduce costs. Compress data to save storage space and enhance query speed.
Autoscaling and serverless computing
Utilize serverless services like AWS Glue and Athena to automatically scale resources based on demand. This ensures cost efficiency and reduces administrative overhead.
Data lake governance
Establish data governance practices to manage data access, security, and compliance. Use AWS Identity and Access Management (IAM) to control access to data lake resources.
Monitoring and optimization
Implement monitoring and logging solutions to track data lake performance and identify bottlenecks. Leverage AWS CloudWatch and AWS Glue DataBrew profiling to gain insights and optimize resource utilization.
Also Read: Who is responsible for protecting data in the Cloud?
Conclusion
Leveraging AWS services to build and scale data lakes is a key step in transforming data chaos into data mastery. With PeoplActive’s expertise and support, organizations can effectively design, implement, and optimize their data lakes, ensuring data is managed, secure, and accessible. PeoplActive’s comprehensive solutions enable businesses to unlock valuable insights, make data-driven decisions, and drive innovation through advanced analytics capabilities. By hiring AWS talent with PeoplActive, organizations can confidently navigate the complexities of data lakes and achieve success in their data management initiatives, ultimately gaining a competitive advantage in today’s data-driven landscape.
Original Post URL: https://securityboulevard.com/2023/05/from-data-chaos-to-data-mastery-how-to-build-and-scale-data-lakes-with-aws-services/
Category & Tags: Cloud Security,Security Bloggers Network,cloud computing – Cloud Security,Security Bloggers Network,cloud computing
Views: 0


















































