Source: www.nist.gov – Author: Joseph Near, David Darais.
This post is part of a series on privacy-preserving federated learning. The series is a collaboration between NIST and the UK government’s Responsible Technology Adoption Unit (RTA), previously known as the Centre for Data Ethics and Innovation. Learn more and read all the posts published to date at NIST’s Privacy Engineering Collaboration Space or RTA’s blog.
The last two posts in our series covered techniques for input privacy in privacy-preserving federated learning in the context of horizontally and vertically partitioned data. To build a complete privacy-preserving federated learning system, these techniques must be combined with an approach for output privacy, which limit how much can be learned about individuals in the training data after the model has been trained.
As described in the second part of our post on privacy attacks in federated learning, trained models can leak significant information about their training data—including whole images and text snippets.
Training with Differential Privacy
The strongest known form of output privacy is differential privacy. Differential privacy is a formal privacy framework that can be applied in many contexts; see NIST’s blog series on this topic for more details, and especially the post on differentially private machine learning.
Techniques for differentially private machine learning add random noise to the model during training to defend against privacy attacks. The random noise prevents the model from memorizing details from the training data, ensuring that the training data cannot later be extracted from the model. For example, Carlini et al. showed that sensitive training data like social security numbers could be extracted from trained language models, and that training with differential privacy successfully prevented this attack.
Differential Privacy for Privacy-Preserving Federated Learning
In centralized training, where the training data is collected on a central server, the server can perform the training and add noise for differential privacy all at once. In privacy-preserving federated learning, it can be more difficult to determine who should add the noise and how they should add it.
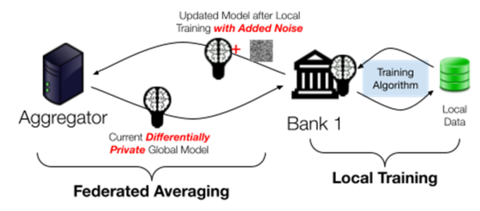
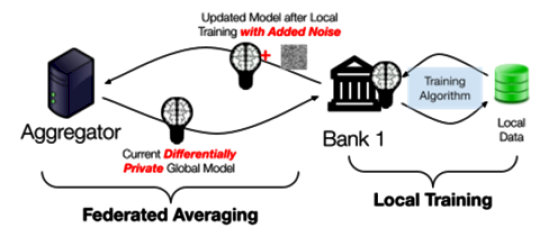
Credit: NIST
For privacy-preserving federated learning on horizontally partitioned data, Kairouz et al. present a variant of the FedAvg approach described in our fourth post. In this approach, visualized, each participant performs local training, then adds a small amount of random noise to their model update before aggregating it with the updates of other participants. If each participant correctly adds noise to their update, then the new aggregated model will contain sufficient noise to ensure differential privacy. This technique provides output privacy, even in the case of a malicious aggregator. The Scarlet Pets team used a variant of this approach in their winning solution for the UK-US PETs Prize Challenges.
In the case of vertically partitioned data, ensuring differential privacy can be complicated. The noise required for differential privacy cannot be added before entity alignment, because it will prevent data attributes from matching up correctly. Instead, the noise must be added after entity alignment, either by a trusted participant or via techniques like homomorphic encryption or multiparty computation.
Training Highly Accurate Differentially Private Models
The random noise required for differential privacy can affect model accuracy. More noise generally leads to better privacy, but worse accuracy. This tradeoff between accuracy and privacy is often called the privacy-utility tradeoff.
For some kinds of machine learning models, including linear regression models, logistic regression models, and decision trees, this tradeoff is easy to navigate – the approach described earlier often works to train highly accurate models with differential privacy. In the UK-US PETs Prize Challenges, both the PPMLHuskies and Scarlet Pets teams used similar techniques to train highly accurate models with differential privacy.
For neural networks and deep learning, the sheer size of the model itself makes training with differential privacy more difficult – larger models require more noise to achieve privacy, which can significantly reduce accuracy. While these kinds of models were not part of the UK-US PETs Prize Challenges, they are increasingly important across all applications of generative AI, including large language models.
Recent results have shown that models pre-trained on publicly available data (without differential privacy) and then fine-tuned with differential privacy can achieve much higher accuracy than models trained only with differential privacy. For example, Li et al. show that pre-trained language models can be fine-tuned with differential privacy and achieve nearly the same accuracy as models trained without differential privacy. These results suggest that for domains where publicly available data can be used for pre-training—including language and image recognition models—privacy-preserving federated learning that achieves both privacy and utility is feasible.
This approach does not offer any privacy protection for the public data used during pre-training, so it’s important to ensure that use of this data respects relevant privacy and intellectual property rights (the legal and ethical considerations around this are outside of the scope of this blog series).
Coming up next
In our next post, we’ll discuss implementation challenges when deploying privacy-preserving federated learning in the real world.
About the author
Original Post url: https://www.nist.gov/blogs/cybersecurity-insights/protecting-trained-models-privacy-preserving-federated-learning
Category & Tags: –
Views: 0


















































